Continual Learning (CL) involves training a machine learning model in a sequential manner to learn new information while retaining previously learned
tasks without the presence of previous training data. Although there has been significant interest in CL,
most recent CL approaches in computer vision have focused on convolutional architectures only.
However, with the recent success of vision transformers, there is a need to explore their potential for CL.
Although there have been some recent CL approaches for vision transformers, they either store training instances of previous tasks or require a task identifier during test time, which can be limiting.
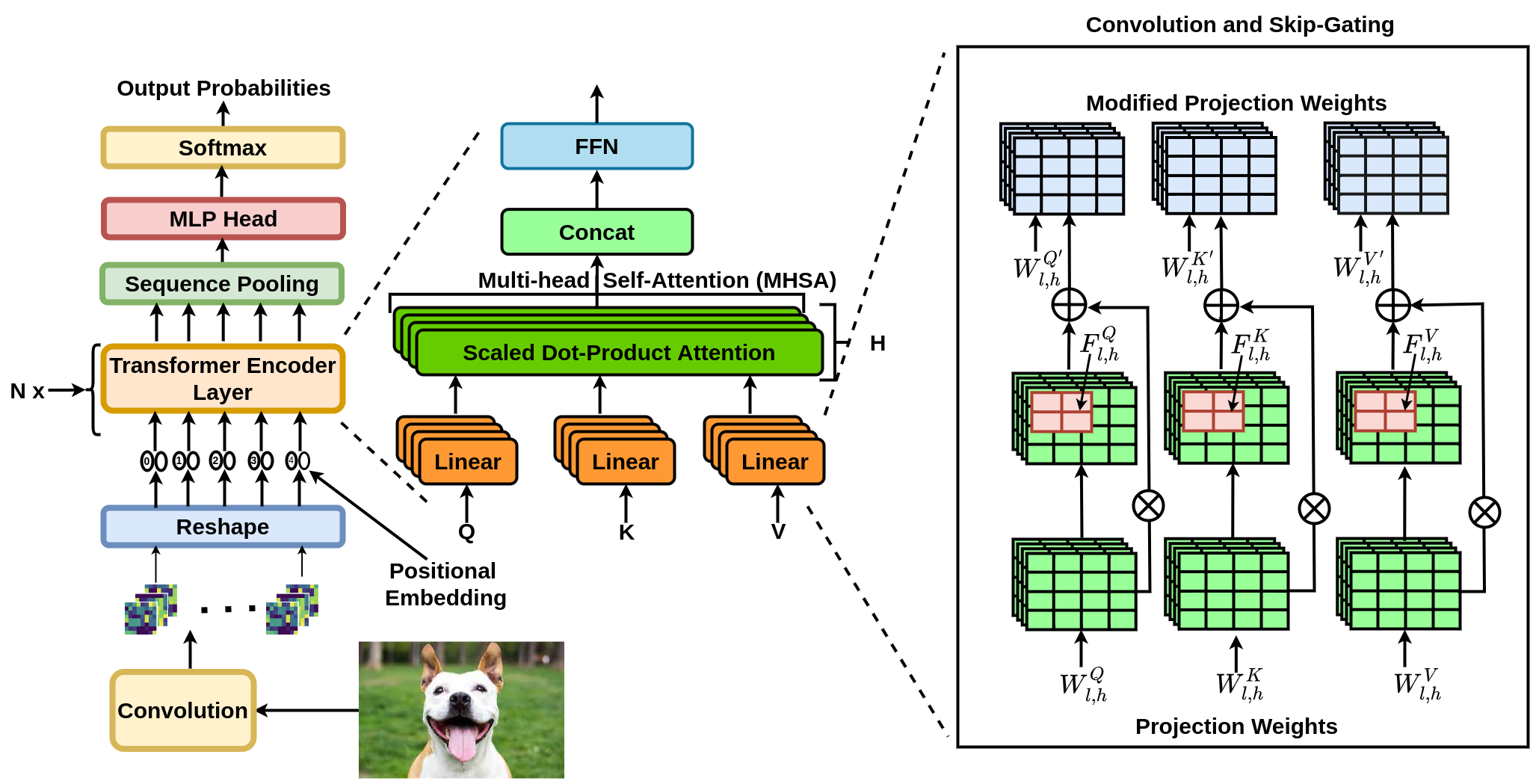
This paper proposes a new exemplar-free approach for class/task incremental learning called ConTraCon, which does not require task-id to be explicitly present during inference and avoids the need for storing previous training instances.
The proposed approach leverages the transformer architecture and involves re-weighting the key, query, and value weights of the multi-head self-attention layers of a transformer trained on a similar task.
The re-weighting is done using convolution, which enables the approach to maintain low parameter requirements per task.
Additionally, an image augmentation-based entropic task identification approach is used to predict tasks without requiring task-ids during inference.
Experiments on four benchmark datasets demonstrate that the proposed approach outperforms several competitive approaches while requiring fewer parameters.